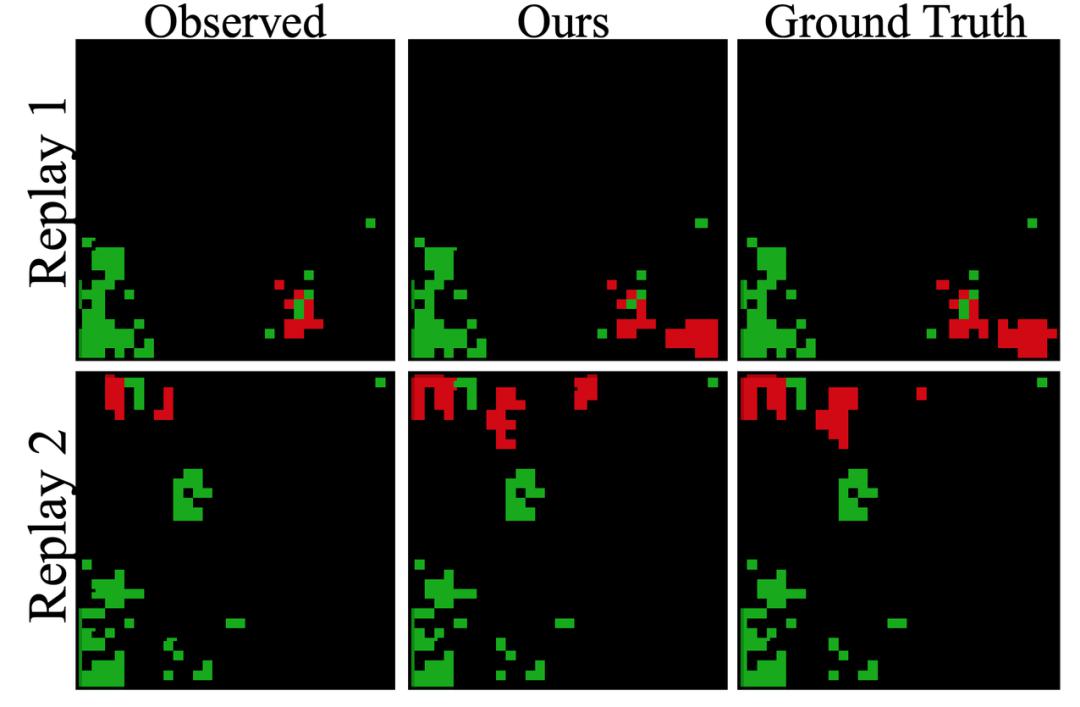
对于广大星际争霸迷来说,地图全开作弊代码「Black sheep wall」应该是再熟悉不过了!如何根据现有状态预测未知信息是博弈过程中举足轻重的一环。日前,韩国三星公司的研究人员在星际争霸游戏中,将预测战争迷雾背后的作战单位信息建模为了一个部分可观察马尔科夫决策过程,并使用基于 GAN 的方法实现了当前性能最佳的战争迷雾去雾算法。
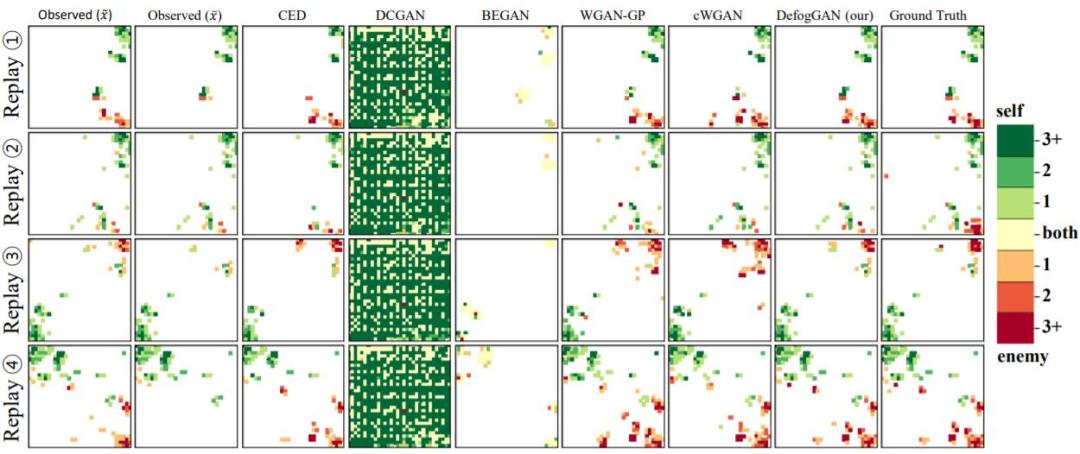
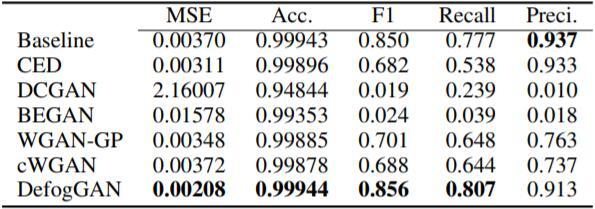
本文提出了 DefogGAN,这是一种推断即时战略(Real-Time Strategy,RTS)游戏中战争迷雾后的隐藏信息状态的生成式方法。给定一个部分可观测的状态,DefogGAN 可以将游戏的去雾图像作为预测信息生成。这样的信息可以创造战略智能体。DefogGAN 是一种条件 GAN 的变体,它使用了金字塔重建损失,从而在多个特征分辨率尺度上进行优化。本文使用一个大型专业的星际争霸录像数据集验证了 DefogGAN。结果表明 DefogGAN 可以预测敌方建筑物和作战单位,准确率与职业玩家相当,并且比当前最佳的去雾模型的性能更好。
AlphaGo 的成功为人工智能在游戏中的应用(Game AI)带来了极大的关注。通过深度强化学习训练的智能体可以在国际象棋、围棋和 Atari 等经典游戏中轻而易举地胜过人类。随着任务环境越来越复杂,实时战略游戏(RTS)成为了一种评估最先进的学习算法的方式。如今,Game AI 为机器学习带来了全新的机遇和挑战。开发 Game AI 的好处十分广泛,不仅限于游戏应用中。在科学中应用智能体(例如,在有机化学领域中预测的蛋白质折叠)和企业的商业服务(例如,天机器人)的探索,使 Game AI 正走向一个新的时代。
在本文中,作者提出的 DefogGAN 采用生成式方方法补全因战争迷雾造成的显示给玩家的不完全信息。本文使用星际争霸作为实验场景——这是一款 RTS 游戏,游戏中有三个均衡的种族供玩家选择,玩家要建立完全不同的游戏风格和战略。在发行逾二十年后,星际争霸依然是一款非常受欢迎的电子竞技游戏。为了实现让 Game AI 超越高水平人类玩家的艰巨目标,本文作者使用超过 30,000 场的职业玩家的游戏录像训练了 DefogGAN。在星际争霸中,这样的目标是很难实现的。因为星际争霸长期以来一直广受欢迎,玩家们开发出了各种各样的成熟的游戏策略,除此之外,在电竞现场和暴雪战网(Battle.net)中玩家们还广泛使用了微操技术。
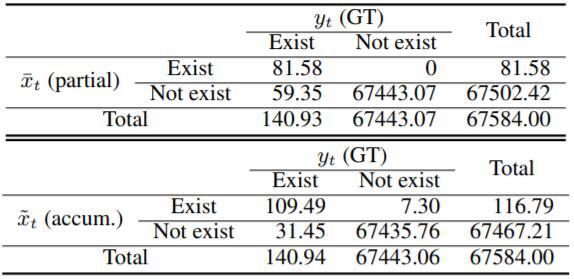
战争迷雾指在某个没有友方单位的区域中,不能获得视野和信息,这样的区域包括所有之前探索过但目前无人值守的区域。部分可观察马尔科夫决策过程(Partially Observable Markov Decision Process,POMDP)最适合描述战争迷雾问题。一般而言,POMDP 为真实世界中大多数有大量未观察到的变量的问题提供了一个实用的表达方式。对 Game AI 来说,解决部分可观察问题是提升性能的关键所在。事实上,许多现有的设计智能 Game AI 的方法都会遇到部分可观察问题。最近,生成模型被用来降低部分可观察问题的不确定性。利用生成模型的预测结果,智能体的性能得到了提升。然而,生成方法无法完全与顶尖的人类职业玩家的高水平侦察技术匹敌。
星际争霸为研究与 Game AI 相关的复杂 POMDP 问题提供了一个绝佳的平台。本文作者利用生成对抗网络,建立了 DefogGAN,它可以根据生成的逼真信息准确预测隐藏在战争迷雾中的对手的状态。根据经验,本文作者发现,GAN 比变分自编码器(Variational Autoencoder,VAE)生成的图像更逼真。为了生成去除战争迷雾的游戏状态,本文作者将原始的 GAN 生成器修改为编码器-解码器网络。
从原理上讲,DefogGAN 是条件 GAN 的变体。通过使用跳跃连接,DefogGAN 生成器利用根据编码器-解码器结构学习到的残差进行训练。除了 GAN 的对抗损失,本文作者还设置了有雾和去雾游戏状态间的重建损失,来强调单位位置和数量的回归。本文的贡献如下:
•开发了 DefogGAN,可以解析有战争迷雾的游戏状态,得到有用的获胜信息。DefogGAN 是最早的基于 GAN 处理星际争霸中的战争迷雾问题的方法;
•利用跳跃连接进行残差学习,在不引入任何循环结构的情况下,DefogGAN 以前馈的方式包含过去的信息(序列),更适用于实时使用的情况;
•本文作者在模型简化实验和其它设置(如针对提取出的游戏片段和当前最先进的去雾策略进行测试)中,对 DefogGAN 进行了实证验证。
本文涉及的数据集、源代码和预训练网络对公众开放,可以在线访问。
在 t 时刻,DefogGAN 根据部分可观察(有雾)状态,生成了完全的观察(去雾)状态。在星际争霸中,完全观察状态包括在给定时间下,所有友方和敌方单元的确切位置。图 2 展示了 DefogGAN 的架构。本文作者对当前的部分可观察状态的输入计算得到的特征图进行求和池化。在过去的观测结果的特征图进入生成器前,要和当前状态累积并拼接。本文作者用预测的可观察状态和实际的完全观察状态间的重建损失和判别器的对抗损失训练生成器。
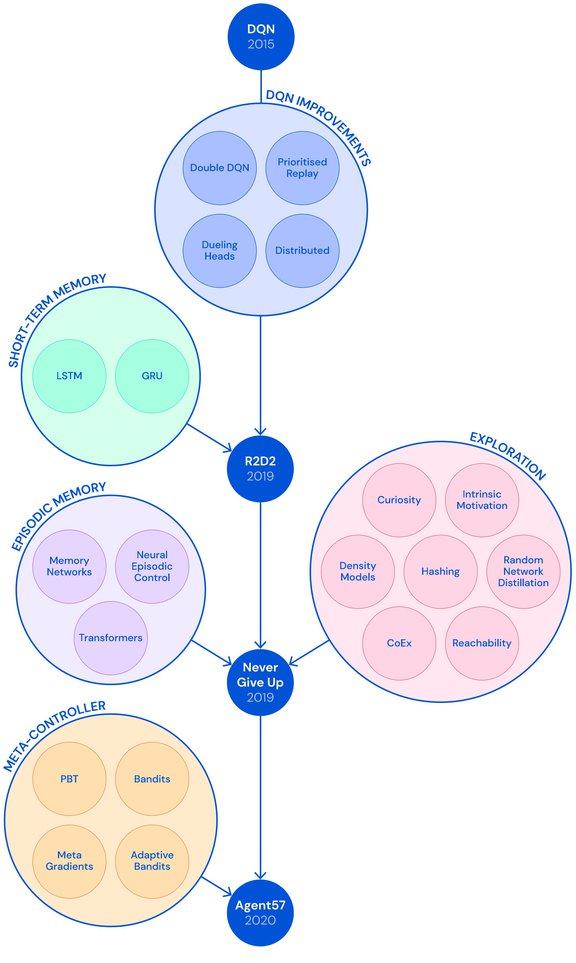
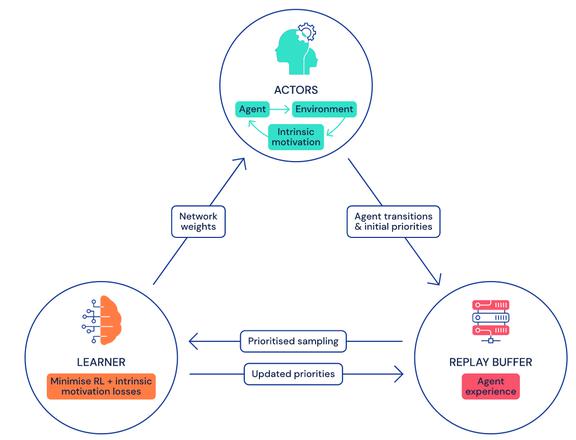
至于 Agent57 的具体架构,它通过将众多 actor 馈入到学习器可以采样的一个中央存储库(经验回溯缓冲器),进而实现数据收集。该缓冲器包含定期剪枝的过渡序列,它们是在与独立、按优先级排列的游戏环境副本交互的 actor 进程中产生的。
DeepMind 团队使用两种不同的 AI 模型来近似每个状态动作的价值(state-action value),这些价值能够说明智能体利用给定策略来执行特定动作的好坏程度,这样就使得 Agent57 智能体可以适应与奖励相对应的均值与方差。他们还整合了一个可以在每个 actor 上独立运行的元控制器,从而可以在训练和评估时适应性地选择使用哪种策略。